TL;DR: From combining RL with LLMs through more efficient MetaRL and updates in an environment design to classic hyperparameter optimization, these are some of our top picks, plus a selection of our own AutoRL projects at the end of this post. So sit back and enjoy some of the most interesting AutoRL papers of 2023.
2023 in AutoRL

GPT-generated image depicting AutoRL
What a year 2023 has been in machine learning! Beyond the obvious explosion in LLM capability, it was also a great year for all things AutoRL. From combining RL with LLMs through more efficient MetaRL and updates in an environment design to classic hyperparameter optimization, these are some of our top picks, plus a selection of our own AutoRL projects at the end of this post. So sit back and enjoy some of the most interesting AutoRL papers of 2023.
LLMs and more in RL
Language models have been on everyone’s mind this last year, and with good reason. So it’s only natural to try and use the capabilities of LLMs as common sense or reasoning models to support RL. LLMs have successfully been used as policies and curriculum generation mechanisms in Voyager [Wang et al., ArXiv], but also for finding expressive rewards signals in robotics (Eureka [Ma et al., ArXiv]) and exploration environments like MiniHack (Motif [Klissarov et al., ALOE@NeurIPS]).
Key components of the Voyager LLM-based agent. Image credit: Voyager paper
Agents [Zhou et al., ArXiv] is a user-friendly library that enables non-specialists to build state-of-the-art autonomous language agents without much coding. Generative Agents [Park et al., ArXiv] introduces architectural and interaction patterns that fuse LLMs with computational software agents that simulate believable human behaviour in a sandbox.

An overview of the Agents framework. Image credit: Agents paper
Robotics had some eye-catching works this year. [Brohan et al., ArXiv] trained Robotic Transformer 2 (RT-2), a vision-language-action (VLA) model based on vision-language models (VLMs), that can plan from both image and text commands. [Hansen et al., ArXiv] (TD-MPC2) train multi-task agents with world models that scale up with model size (up to 319M) on continuous control tasks with a single set of hyperparameters.
Meta-RL
The Meta-RL year started off strong with an excellent survey on the field in January [Beck et al., ArXiv]. It is a great resource on different Meta-RL paradigms and the work that has been done in this domain.
A big topic in Meta-RL this year was learning RL algorithms - unlike the approaches often used in the past, however, this year, in-context RL was the dominant idea for learning RL. From AdA, which showed rapid in-context adaptation to new task variations [Bauer et al., ICML], to learning an RL algorithm from supervised pre-training (DPT) [Lee et al., ArXiv] or adapting to new tasks [Chandra et al., FMDM@NeurIPS] in-context, this seems to be a promising future direction for meta-learned RL algorithms.

In-context adaption with AdA. Image credit: AdA paper
Environment Design
Generating challenging training environments and curricula has continued to be an important AutoRL topic in 2023. [Xie et al., ArXiv] automatically generate dense reward functions using LLMs. Similarly, [Zhang et al., CoRL 2023] learn to solve long-horizon tasks zero-shot by growing a library of learned skills with supervision by LLMs.
In curriculum generation, [Bajaj et al., ICAPS 2023] combine learning from demonstrations and curriculum learning to perform Automated Curriculum Learning from Demonstrations on sparse reward tasks. [Samvelyan et al., ICLR 2023] apply environment design to the multi-agent setting while keeping the abilities of other agents in mind in MAESTRO. Meanwhile, [Jackson et al., NeurIPS 2023] show that curricula are not only useful for learning policies but also in learning better RL algorithms.

Reward generation using Text2Reward. Image credit: Text2Reward paper
RL Hyperparameters
[Beukmann et al., NeurIPS 2023] generalise to new transition dynamics using a hypernetwork that generates the weights of an adapter module that conditions the behaviour of an agent on the environment context. [Lan et al., ArXiv] train an adaptive optimizer with inductive biases to generalise on learning rate control from toy tasks to complex Brax tasks. [Sabbioni et al., ArXiv] meta-learn setting the learning rate adaptively for sampled contextual test tasks.
[Yuan et al., ICML 2023] use a multi-armed bandit formulation, dubbed Automatic Intrinsic Reward Shaping, to select between different exploration strategies on MiniGrid, Procgen, and DeepMind Control Suite. This could be a promising strategy for dynamic Algorithm Selection in RL.

Intrinsic reward selection via UCB. Image credit: Automatic Instrinsic Reward Shaping paper
Benchmarks & Libraries
[Aitchison et al., ICML] Atari-5 selects a representative subset of 5 of 57 Atari games that can be used to predict median performance on all 57 games within 10% of the true value. Since a lot of (Auto)RL research is conducted on variations of the ALE, this could make such work much more efficient to run.
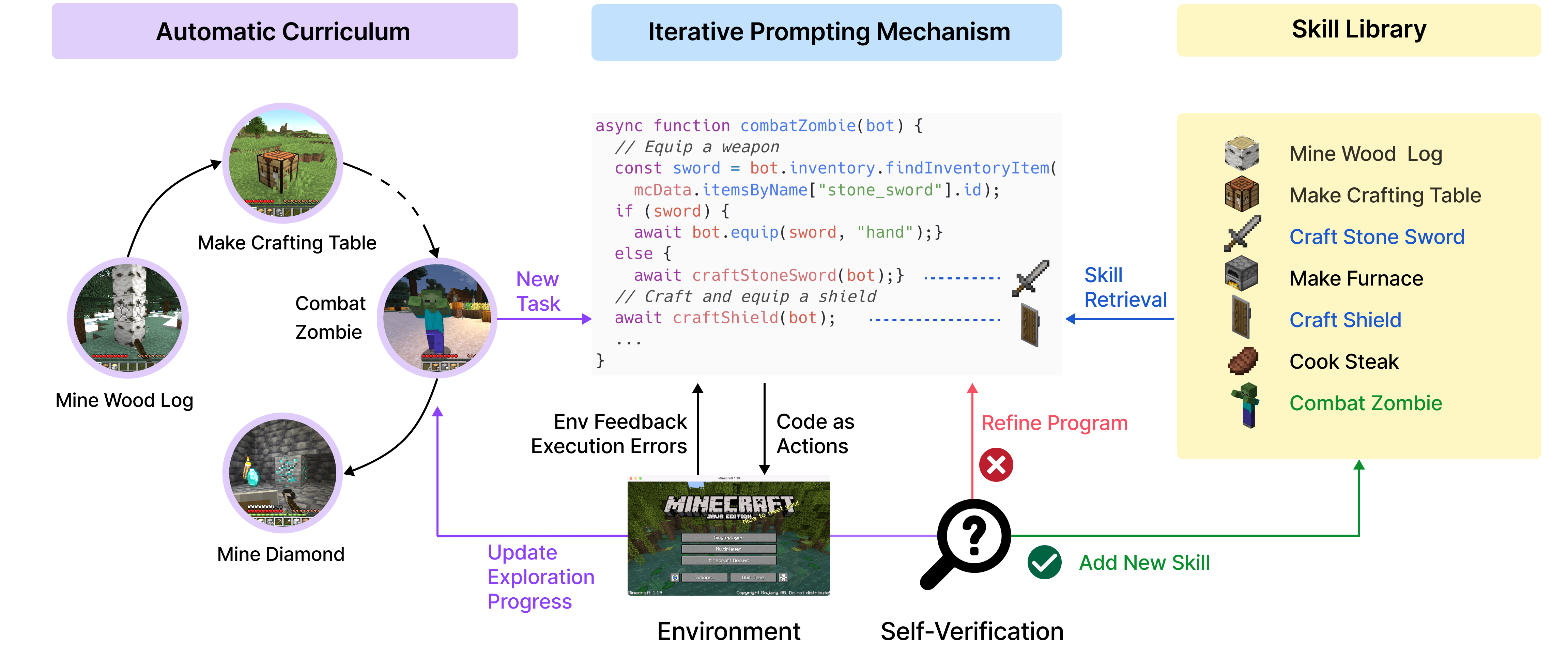
The same goes for the JAXification of RL – while benchmarks like XLand and JaxMARL as well as training libraries like PureJAX aren’t directly targeted at AutoRL, they certainly make AutoRL research much more accessible.
On the side of new AutoRL focus libraries, minimax and Syllabus both aim to make curriculum learning faster, easier to implement, and more comparable. They take slightly different approaches, though: while Syllabus offers a way of implementing the curriculum that works with different base algorithms (their examples include CleanRL and RLLib), minimax uses its own PPO implementation to keep evaluations directly comparable. Together they should cover most curriculum generation use cases, hopefully bringing a bit more standardisation to the field.
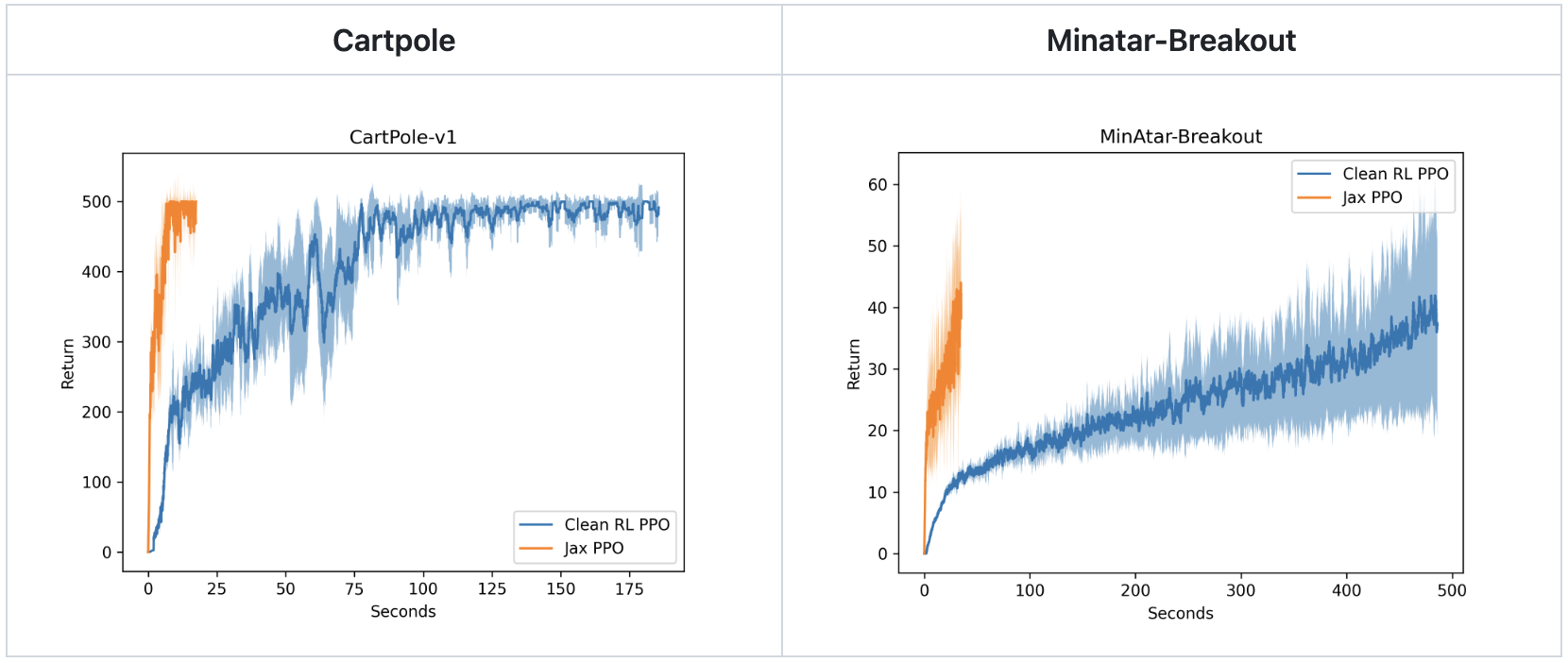
Speedups with PureJAX. Image credit: PureJAX repo
AutoRL.org Projects

Testing robustness against reward delay in DQNs on Atari. Image credit: MDP Playground paper
Of course, we weren’t idle throughout the year either. One important topic was benchmarking this year, as you can see in “MDP Playground: An Analysis and Debug Testbed for Reinforcement Learning” [Rajan et al., JAIR]. MDP Playground lets you define properties of MDPs, including delayed rewards, stochasticity, image representations, time unit, action range, and more to unit test your algorithms on toy MDPs or test its robustness on standard complex MDPs such as Atari and Mujoco using Gym wrappers.

Hand tuning compared to automatic HPO in RL. Image credit: HPs in RL paper
On the hyperparameter side of things, we go back to the basics in “Hyperparameters in Reinforcement Learning and How To Tune Them” [Eimer et al., ICML] for an investigation into how hard HPO for RL actually is and which existing tools work well for it. We show that automated HPO tools can give us similar results to grid searches for less than 10x the compute and propose best practices of how to incorporate HPO into experiments and reporting for more reproducible RL research. Further, “Gray-Box Gaussian Processes for Automated Reinforcement Learning” [Shala et al., ICLR] discusses how to fuse hyperparameter configurations, reward-curve information, as well as optimization budgets to perform efficient bayesian optimization specifically for AutoRL.

Improvement of Grey-Box GPs on PPO compared to PBT variations. Image credit: Grey-Box GP paper
Going beyond that, in “AutoRL Hyperparameter Landscapes” [Mohan et al., AutoML], we examine the relationship between hyperparameters, performance, and training time: how important are hyperparameter schedules in RL? We analyze this using landscape analysis across different types of hyperparameters (discounting, learning speed, and exploration) and agents (value-based and policy-based) and observe that the optimal regions of hyperparameters change as the agent trains, reaffirming the need for prioritising dynamic hyperparameter adaptations in RL.
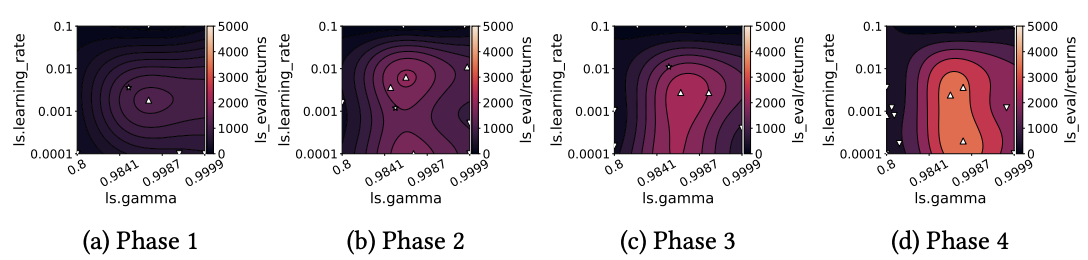
Development of optimal learning rate and discount factor values for SAC over time. Image credit: RL Landscapes paper
On the topic of different kinds of learning objectives in Meta-RL and AutoRL, we unify diverse methodologies in Meta-RL and AutoRL under a design-pattern-oriented framework in [Mohan et al., 2023] highlighting the crucial role of structural integration in learning processes. Adding Structured RL into our research toolkit promises to enhance our understanding and capabilities in Meta-RL and Auto-RL significantly.
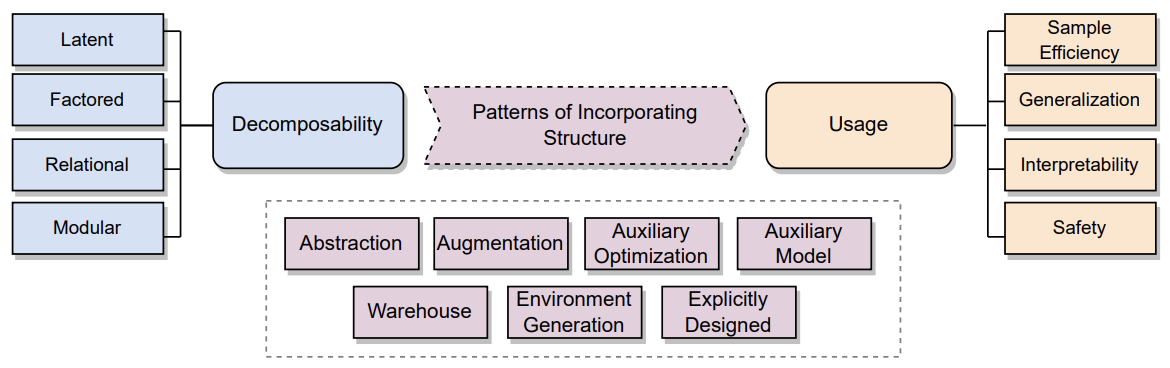
Overview of how to incorporate structure into RL. Image credit: Structure in RL paper
These are our best of 2023 – what have we missed, what are your highlights? Hopefully, 2024 can give us a similarly diverse range of exciting AutoRL research & software. Apart from the usual suspects, the RL conference with its first edition as well as COLLAs and the AutoML-Conf with their fourth and third editions respectively are likely venues for great AutoRL work in the coming year. So happy New Year and happy researching!