TL;DR: From integrating RL with VLMs and LLMs to hyperparameter tuning, environment design, and generalization, 2024 was packed with innovation. We’ve highlighted top advancements in AutoRL and included a selection of our own projects at the end. Dive in to explore the cutting-edge in RL from the past year!
Making Reinforcement Learning Work Out of the Box: A 2024 Overview
2024 was a big year for RL in general and AutoRL specifically. Here we collect some of our highlights from last year.
AutoML for RL
AutoML for RL remains a key focus area. Normalization and Effective Learning Rates in RL by Lyle et al. introduces Normalize-and-Project, maintaining consistent learning rates in dynamic environments, particularly useful for long-term training. For hyperparameter tuning, Generalized PBT by Bai et al. refines Population-Based Training with pairwise learning to better balance exploration and exploitation, making RL algorithms more robust. Meanwhile, Adaptive Q-Network by Vincent et al. tackles on-the-fly hyperparameter tuning within RL training for improved real-world applicability. In EVA: Explained Variance Adaptation Paischer et al. optimize initialization strategies to speed up convergence in fine-tuning and improve performance across multiple domains.
Additional work has further examined the performance and consistency of RL hyperparameters in Small Batch Deep Reinforcement Learning and On the Consistency of Hyper-parameter Selection in Value-based Deep Reinforcement Learning, both by Obando-Ceron et al. Showing that this remains an open challenge limiting the applicability of RL algorithms.
A central challenge in RL is evaluating agent performance and selecting suitable algorithms. Estimating Agent Skill in Continuous Action Domains by Archibald et al. introduces a Bayesian framework to separate decision-making and execution skills for robust, fine-grained assessments. Complementing this, the tool presented in How to Choose a Reinforcement-Learning Algorithm by Bongratz et al. simplifies algorithm selection by providing an interactive guide that aligns methods with task requirements, further reducing barriers for practitioners. Of course the final step would be to do this automatically. Just in case you’re still looking for research inspiration!
Improving generalization and efficiency in experience replay is another central theme. Investigating the Interplay of Prioritized Replay and Generalization by Panahi et al. reveals trade-offs in prioritized sampling and proposes mitigations for instability, while Averaging n-step Returns Reduces Variance in RL by Daley et al. introduces compound returns that enhance sample efficiency without sacrificing performance.
Environment Design
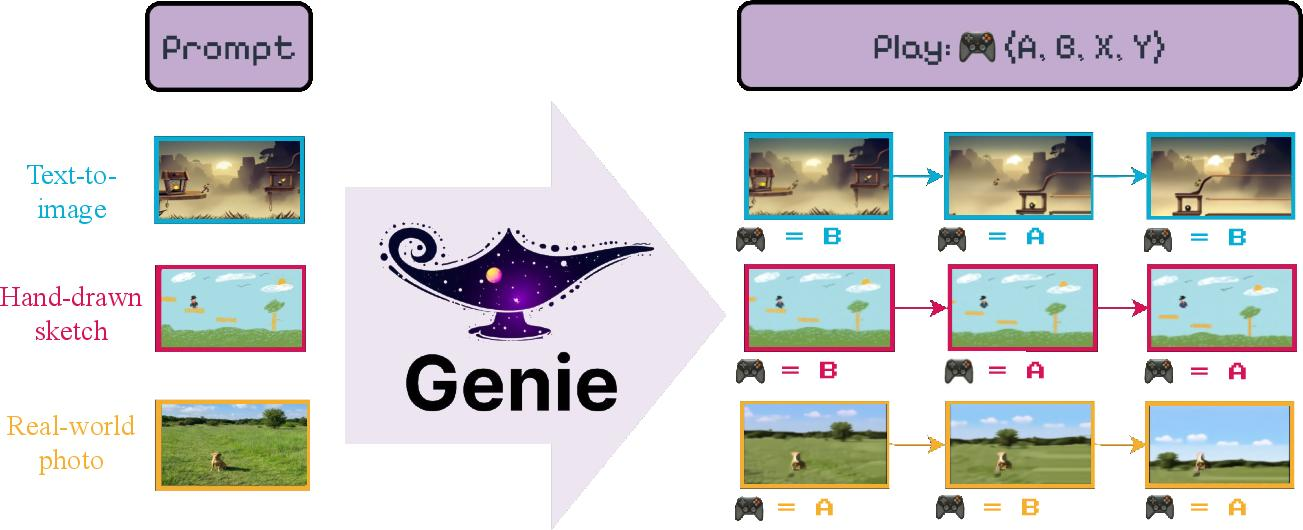
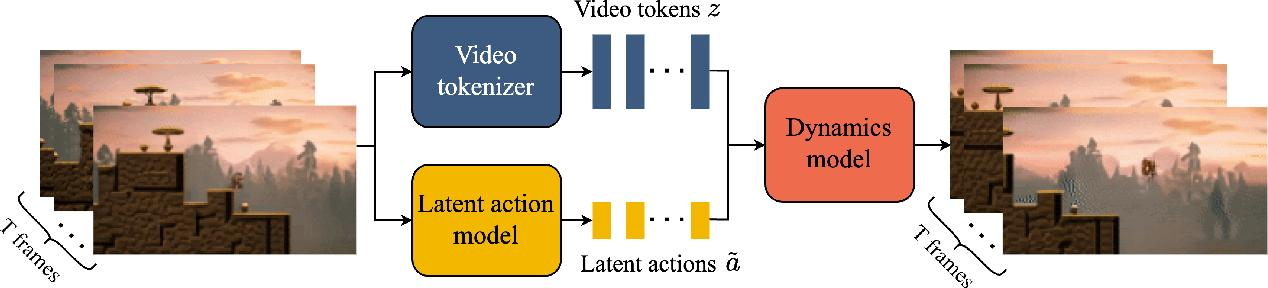
Environment design and model-based methods are also undergoing rapid transformation. Genie by Bruce et al. and Genie 2 by Parker-Holder et al. propose generative models that create interactive environments from unlabelled videos, enabling agents to learn diverse behaviors. Bridging pretraining and deployment, PreLAR by Zhang et al. introduces action-conditioned pretraining for world models, improving sample efficiency. Meanwhile, DrEureka by Ma et al. harnesses LLMs to automate sim-to-real transfer, Action Abstractions for Amortized Sampling by Boussif et al. enhances exploration by abstracting high-level actions, Causality-Guided Self-Adaptive Representations Yang et al. adapts to unseen dynamics via causal learning, and CurricuLLM by Ryu et al. uses LLMs to design task curricula, accelerating the learning of complex robot skills.
Reward engineering and the offline RL front continue to see impactful innovations. Reward Centering by Naik et al. stabilizes training by normalizing reward distributions, enhancing consistency across tasks. Image-Based Dataset Representations for Predicting Learning Performance by Mateos-Meleri et al. leverages convolutional models to predict policy outcomes and guide dataset optimization.
LLMs and VLMs are exciting tools for reward design and policy learning. GenRL aligns VLMs with world models, enabling tasks to be specified through vision and language prompts, improving multi-task generalization. Similarly, Real-World Offline RL from Vision-Language Model Feedback by Venkataraman et al. automates reward labeling from suboptimal datasets, and Online Intrinsic Rewards from LLM Feedback by Zheng et al. synthesizes dense natural-language-based intrinsic rewards.

Beyond reward design, LLMs and VLMs reshape how RL agents interact with their environments. ROCKET-1 by Cai et al. employs visual-temporal context prompting to enhance spatial reasoning in open-world tasks, while LLaRA by Liao et al. uses conversation-style data augmentation to enrich vision-language policy learning for more sophisticated robotic behaviors. In Adaptive Planning with Generative Models under Uncertainty Jutras-Dubé et al. reduce replanning frequency without compromising performance, making generative models more practical.
Robotics
The field of AutoRL has made strides in robotics as well. Online Foundation Model Selection in Robotics by Li et al. balances cost and performance between open-source and closed-source models, while Learning Robot Soccer from Egocentric Vision by Tirumala et al. demonstrates an end-to-end approach for multi-agent policies trained purely from on-board vision, expanding RL’s applicability to complex robotic tasks without privileged information.
Foundation models have also made big strides in unsupervised methods for Robotics. Motivo by Tirinzoni et al. introduces a behavioral foundation model that leverages unsupervised reinforcement learning with forward-backward representations and conditional policy regularization to train a humanoid capable of zero-shot whole-body control across tasks like motion tracking, goal-reaching, and reward optimization. RL Zero: Zero-Shot Language to Behaviors without any Supervision by Sikchi et al. demonstrates zero-shot policy learning by grounding language commands into behaviors without any supervision. Similarly, LAPA (Latent Action Pretraining) by Ye et al. presents an unsupervised approach for pretraining robotic foundation models on web-scale data. By learning discrete latent actions and finetuning on a small set of labeled trajectories, LAPA enables generalization to novel tasks and unseen objects in both simulated and real-world environment.
Benchmarks and Frameworks
Benchmarks and frameworks are critical for driving the field forward. Kinetix by Matthews et al. introduces a procedurally generated physics-based task space for pretraining generalist RL agents, demonstrating the viability of large-scale pretraining. BALROG by Paglieri et al. provides a comprehensive benchmark to evaluate LLM and VLM decision-making in dynamic environments, while VisualAgentBench by Liu et al. focuses on testing multimodal agents in diverse, real-world-inspired scenarios. Lastly, frameworks like AutoRL X by Franke et al. bring RL to the web with a dynamic interface for visualizing and managing RL workflows, improving accessibility and collaboration. These benchmarks push the boundaries of evaluation and provide clear goals for future research.
First AutoRL Workshop
A particular highlight of the year was, of course, the first AutoRL workshop at ICML. It hosted a diverse set of great work (see all papers here), headed by our three best paper award winners Can Learned Optimization Make Reinforcement Learning Less Difficult? by Goldie et al., BOFormer: Learning to Solve Multi-Objective Bayesian Optimization via Non-Markovian RL by Hung et al. and Self-Exploring Language Models: Active Preference Elicitation for Online Alignment by Zhang et al.. Furthermore, we had great invited talks by Chelsea Finn, Roberta Raileanu, Pierluca D’Oro, Michael Dennis and Pablo Samuel Castro on everything from RL for robotics, in-context RL, AI-assisted agent design, learning interactive environments and the ALE as a benchmark for AutoRL. The videos are publicly available on the ICML workshop page.
Our Work
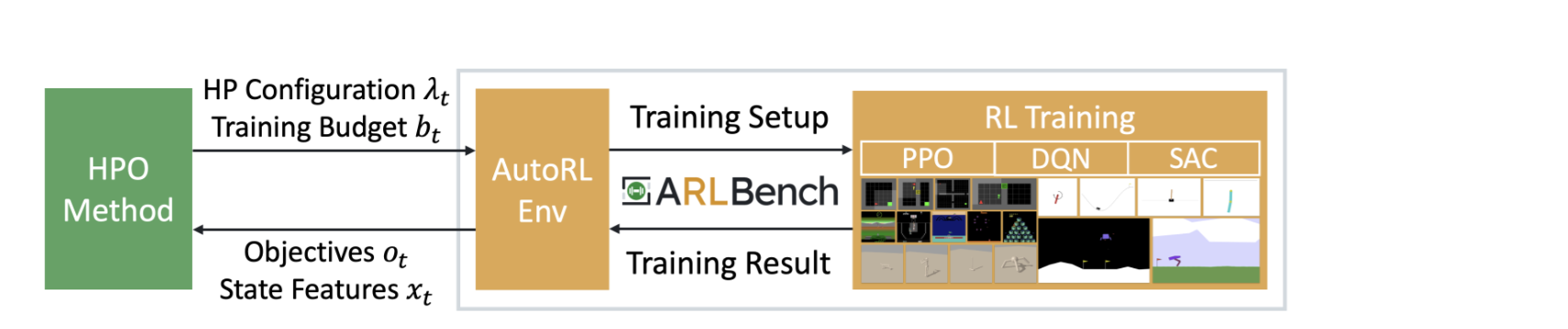
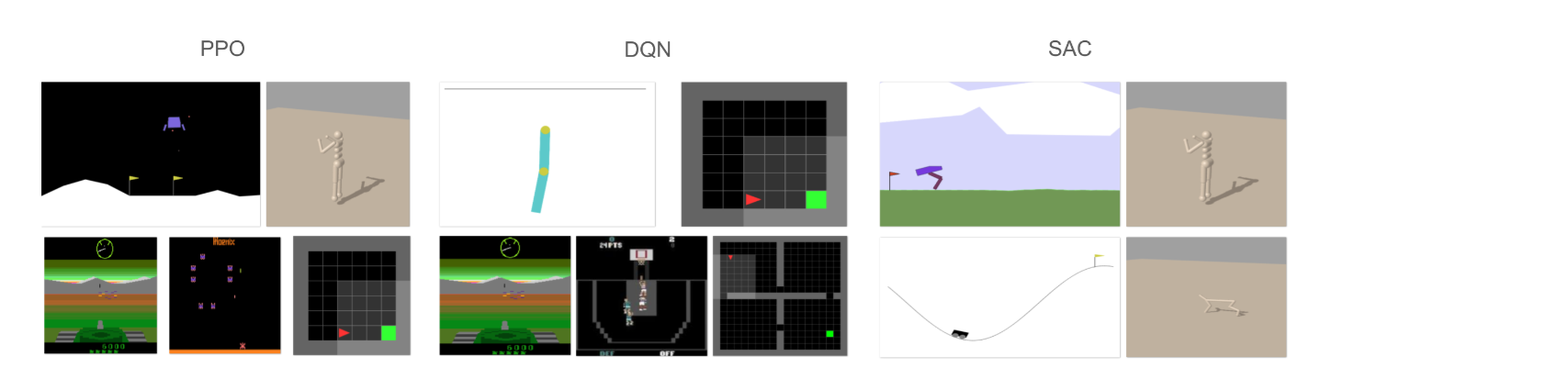
Of course, AutoRL.org itself has not been idle. Our own work this year includes HPO-RL-Bench by Shala et al. and ARLBench by Becktepe et al., two benchmarks for hyperparameter optimization based on tabular performance data and rapid execution respectively. Combined, they make benchmarking HPO for RL less computationally expensive. Dierkes et al. show the benefits of joint optimization for these critical components in Combining Automated Optimisation of Hyperparameters and Reward Shape. Works like Contextual World Models by Prasanna et al. and Inferring Behavior-Specific Context Improves ZeroShot Generalization in Reinforcement Learning by Camaret et al. expand our understanding of generalization and how context can improve it. One-shot World Models Using a Transformer Trained on a Synthetic Prior by Ferreira et al. shows that prior-fitted networks can be used as in-context world models while Hierarchical Transformers are Efficient Meta-Reinforcement Learners Shala et al. use in-context learning to adapt to unseen tasks. Towards Enhancing Predictive Representations using Relational Structure in Reinforcement Learning by Mohan and Lindauer improve representation learning methods in RL by incorporating relational inductive biases in self-predictive RL.
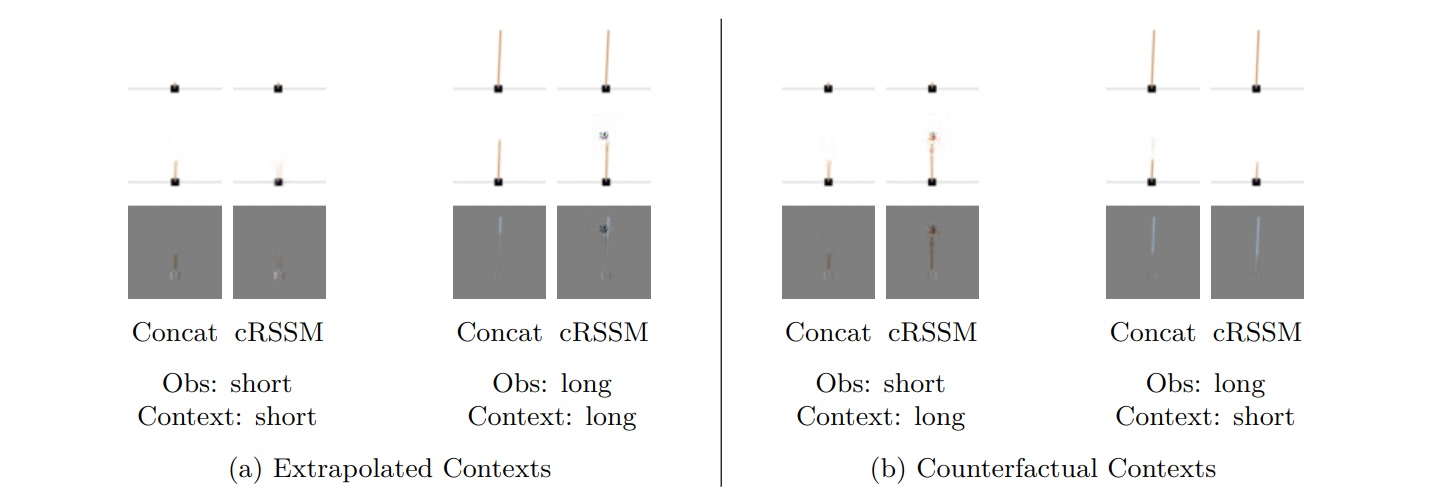
Overall, this has been a very successful year on many fronts: our understanding of how to train RL algorithms increased, integration of foundation models particularly for environment design has made incredible progress and AutoRL is moving forwards both in terms of methods and benchmarking. We’re excited to see what 2025 will bring!